
Unit 14
Biomolecules
“It is the harmonious and synchronous progress of chemical reactions in body which leads to life”.
Objectives
After studying this Unit, you will be able to
- explain the characteristics of biomolecules like carbohydrates, proteins and nucleic acids and hormones;
- classify carbohydrates, proteins, nucleic acids and vitamins on the basis of their structures;
- explain the difference between DNA and RNA;
- describe the role of biomolecules in biosystem.
14.1 Carbohydrates
Carbohydrates are primarily produced by plants and form a very large group of naturally occurring organic compounds. Some common examples of carbohydrates are cane sugar, glucose, starch, etc. Most of them have a general formula, Cx(H2O)y, and were considered as hydrates of carbon from where the name carbohydrate was derived. For example, the molecular formula of glucose (C6H12O6) fits into this general formula, C6(H2O)6. But all the compounds which fit into this formula may not be classified as carbohydrates. For example acetic acid (CH3COOH) fits into this general formula, C2(H2O)2 but is not a carbohydrate. Similarly, rhamnose, C6H12O5 is a carbohydrate but does not fit in this definition. A large number of their reactions have shown that they contain specific functional groups. Chemically, the carbohydrates may be defined as optically active polyhydroxy aldehydes or ketones or the compounds which produce such units on hydrolysis. Some of the carbohydrates, which are sweet in taste, are also called sugars. The most common sugar, used in our homes is named as sucrose whereas the sugar present in milk is known as lactose. Carbohydrates are also called saccharides (Greek: sakcharon means sugar).
Carbohydrates are classified on the basis of their behaviour on hydrolysis. They have been broadly divided into following three groups.
14.1.1 Classification of Carbohydrates
(i) Monosaccharides: A carbohydrate that cannot be hydrolysed further to give simpler unit of polyhydroxy aldehyde or ketone is called a monosaccharide. About 20 monosaccharides are known to occur in nature. Some common examples are glucose, fructose, ribose, etc.
(ii) Oligosaccharides: Carbohydrates that yield two to ten monosaccharide units, on hydrolysis, are called oligosaccharides. They are further classified as disaccharides, trisaccharides, tetrasaccharides, etc., depending upon the number of monosaccharides, they provide on hydrolysis. Amongst these the most common are disaccharides. The two monosaccharide units obtained on hydrolysis of a disaccharide may be same or different. For example, one molecule of sucrose on hydrolysis gives one molecule of glucose and one molecule of fructose whereas maltose gives two molecules of only glucose.
(iii) Polysaccharides: Carbohydrates which yield a large number of monosaccharide units on hydrolysis are called polysaccharides. Some common examples are starch, cellulose, glycogen, gums, etc. Polysaccharides are not sweet in taste, hence they are also called non-sugars.
The carbohydrates may also be classified as either reducing or non-reducing sugars. All those carbohydrates which reduce Fehling’s solution and Tollens’ reagent are referred to as reducing sugars. All monosaccharides whether aldose or ketose are reducing sugars.
14.1.2 Monosaccharides
Monosaccharides are further classified on the basis of number of carbon atoms and the functional group present in them. If a monosaccharide contains an aldehyde group, it is known as an aldose and if it contains a keto group, it is known as a ketose. Number of carbon atoms constituting the monosaccharide is also introduced in the name as is evident from the examples given in Table 14.1
Table 14.1: Different Types of Monosaccharides
| Carbon atoms | General term | Aldehyde | Ketone |
|---|---|---|---|
| 3 | Triose | Aldotriose | Ketotriose |
| 4 | Tetrose | Aldotetrose | Ketotetrose |
| 5 | Pentose | Aldopentose | Ketopentose |
| 6 | Hexose | Aldohexose | Ketohexose |
| 7 | Heptose | Aldoheptose | Ketoheptose |
14.1.2.1 Glucose
Glucose occurs freely in nature as well as in the combined form. It is present in sweet fruits and honey. Ripe grapes also contain glucose in large amounts. It is prepared as follows:
Preparation of Glucose
1. From sucrose (Cane sugar): If sucrose is boiled with dilute HCl or H2SO4 in alcoholic solution, glucose and fructose are obtained in equal amounts.
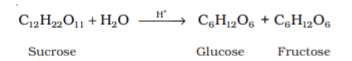
2. From starch: Commercially glucose is obtained by hydrolysis of starch by boiling it with dilute H2SO4 at 393 K under pressure.

Structure of Glucose
Glucose is an aldohexose and is also known as dextrose. It is the monomer of many of the larger carbohydrates, namely starch, cellulose. It is probably the most abundant organic compound on earth. It was assigned the structure given below on the basis of the following evidences:
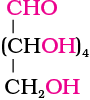
Glucose
1. Its molecular formula was found to be C6H12O6.
2. On prolonged heating with HI, it forms n-hexane, suggesting that all the six carbon atoms are linked in a straight chain.
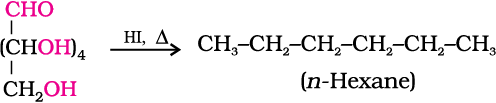
3. Glucose reacts with hydroxylamine to form an oxime and adds a molecule of hydrogen cyanide to give cyanohydrin. These reactions confirm the presence of a carbonyl group (>C = O) in glucose.
4. Glucose gets oxidised to six carbon carboxylic acid (gluconic acid) on reaction with a mild oxidising agent like bromine water. This indicates that the carbonyl group is present as an aldehydic group.
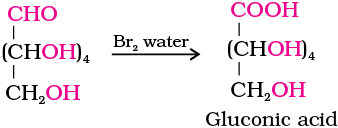
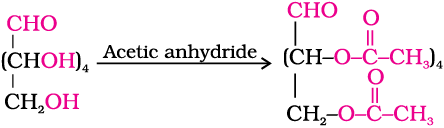
5. Acetylation of glucose with acetic anhydride gives glucose pentaacetate which confirms the presence of five –OH groups. Since it exists as a stable compound, five –OH groups should be attached to different carbon atoms.
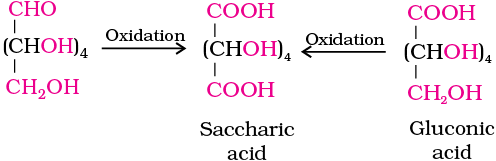
6. On oxidation with nitric acid, glucose as well as gluconic acid both yield a dicarboxylic acid, saccharic acid. This indicates the presence of a primary alcoholic (–OH) group in glucose.
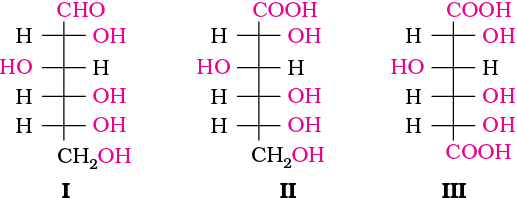
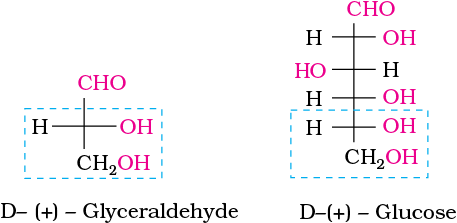
The exact spatial arrangement of different —OH groups was given by Fischer after studying many other properties. Its configuration is correctly represented as I. So gluconic acid is represented as II and saccharic acid as III.
Glucose is correctly named as D(+)-glucose. ‘D’ before the name of glucose represents the configuration whereas ‘(+)’ represents dextrorotatory nature of the molecule. It should be remembered that ‘D’ and ‘L’ have no relation with the optical activity of the compound. They are also not related to letter ‘d’ and ‘l’ (see Unit 10). The meaning of D– and L– notations is as follows.
The letters ‘D’ or ‘L’ before the name of any compound indicate the relative configuration of a particular stereoisomer of a compound with respect to configuration of some other compound, configuration of which is known. In the case of carbohydrates, this refers to their relation with a particular isomer of glyceraldehyde. Glyceraldehyde contains one asymmetric carbon atom and exists in two enantiomeric forms as shown below.

(+) Isomer of glyceraldehyde has ‘D’ configuration. It means that when its structural formula is written on paper following specific conventions which you will study in higher classes, the –OH group lies on right hand side in the structure. All those compounds which can be chemically correlated to D (+) isomer of glyceraldehyde are said to have D-configuration whereas those which can be correlated to ‘L’ (–) isomer of glyceraldehyde are said to have L—configuration. In L (–) isomer –OH group is on left hand side as you can see in the structure. For assigning the configuration of monosaccharides, it is the lowest asymmetric carbon atom (as shown below) which is compared. As in (+) glucose, —OH on the lowest asymmetric carbon is on the right side which is comparable to (+) glyceraldehyde, so (+) glucose is assigned D-configuration. Other asymmetric carbon atoms of glucose are not considered for this comparison. Also, the structure of glucose and glyceraldehyde is written in a way that most oxidised carbon (in this case –CHO)is at the top.
Cyclic Structure of Glucose
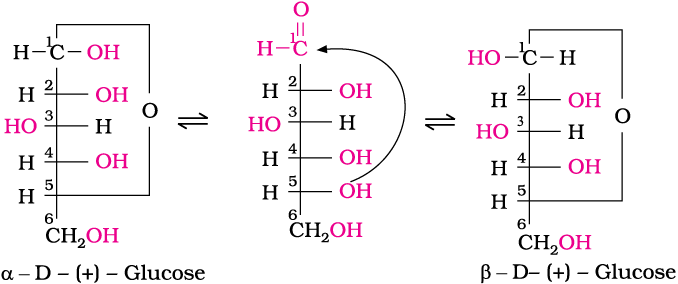
The structure (I) of glucose explained most of its properties but the following reactions and facts could not be explained by this structure.
1. Despite having the aldehyde group, glucose does not give Schiff’s test and it does not form the hydrogensulphite addition product with NaHSO3.
2. The pentaacetate of glucose does not react with hydroxylamine indicating the absence of free —CHO group.
3. Glucose is found to exist in two different crystalline forms which are named as α and β. The α-form of glucose (m.p. 419 K) is obtained by crystallisation from concentrated solution of glucose at 303 K while the β-form (m.p. 423 K) is obtained by crystallisation from hot and saturated aqueous solution at 371 K.
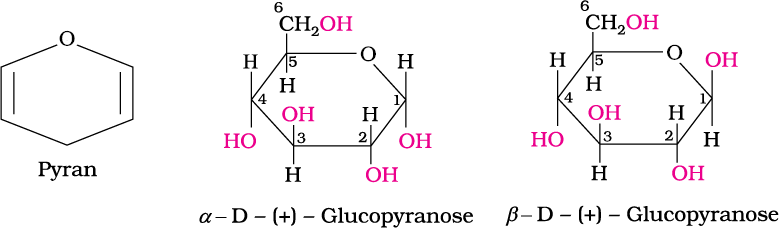
This behaviour could not be explained by the open chain structure (I) for glucose. It was proposed that one of the —OH groups may add to the —CHO group and form a cyclic hemiacetal structure. It was found that glucose forms a six-membered ring in which —OH at C-5 is involved in ring formation. This explains the absence of —CHO group and also existence of glucose in two forms as shown below. These two cyclic forms exist in equilibrium with open chain structure.
Fructose is an important ketohexose. It is obtained along with glucose by the hydrolysis of disaccharide, sucrose. It is a natural monosaccharide found in fruits, honey and vegetables. In its pure form it is used as a sweetner. It is also an important ketohexose.
Structure of Fructose
Fructose also has the molecular formula C6H12O6 and on the basis of its reactions it was found to contain a ketonic functional group at carbon number 2 and six carbons in straight chain as in the case of glucose. It belongs to D-series and is a laevorotatory compound. It is appropriately written as D-(–)-fructose. Its open chain structure is as shown.
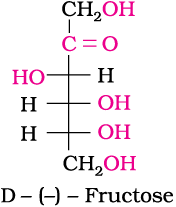
It also exists in two cyclic forms which are obtained by the addition of —OH at C5 to the (![]() ) group. The ring, thus formed is a five membered ring and is named as furanose with analogy to the compound furan. Furan is a five membered cyclic compound with one oxygen and four carbon atoms.
) group. The ring, thus formed is a five membered ring and is named as furanose with analogy to the compound furan. Furan is a five membered cyclic compound with one oxygen and four carbon atoms.
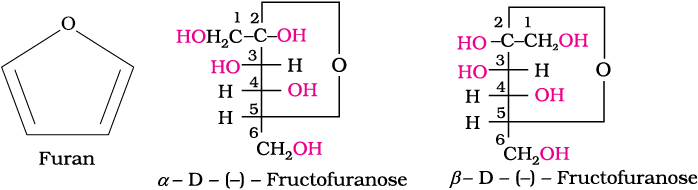
The cyclic structures of two anomers of fructose are represented by Haworth structures as given.
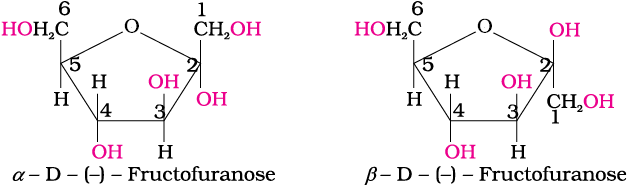
14.1.3 Disaccharides
You have already read that disaccharides on hydrolysis with dilute acids or enzymes yield two molecules of either the same or different monosaccharides. The two monosaccharides are joined together by an oxide linkage formed by the loss of a water molecule. Such a linkage between two monosaccharide units through oxygen atom is called glycosidic linkage.
In disaccharides, if the reducing groups of monosaccharides i.e., aldehydic or ketonic groups are bonded, these are non-reducing sugars, e.g., sucrose. On the other hand, sugars in which these functional groups are free, are called reducing sugars, for example, maltose and lactose.
(i) Sucrose: One of the common disaccharides is sucrose which on hydrolysis gives equimolar mixture of D-(+)-glucose and D-(-) fructose.
![]()
These two monosaccharides are held together by a glycosidic linkage between C1 of α-D-glucose and C2 of β-D-fructose. Since the reducing groups of glucose and fructose are involved in glycosidic bond formation, sucrose is a non reducing sugar.
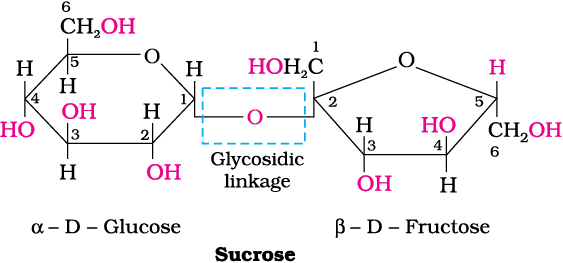
Sucrose is dextrorotatory but after hydrolysis gives dextrorotatory glucose and laevorotatory fructose. Since the laevorotation of fructose (–92.4°) is more than dextrorotation of glucose (+ 52.5°), the mixture is laevorotatory. Thus, hydrolysis of sucrose brings about a change in the sign of rotation, from dextro (+) to laevo (–) and the product is named as invert sugar.
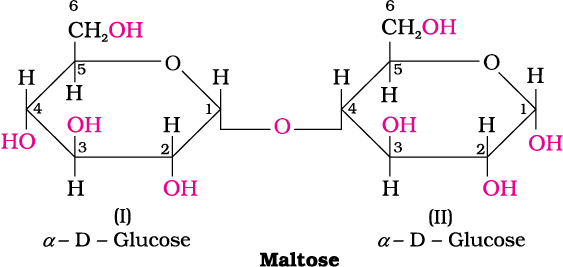
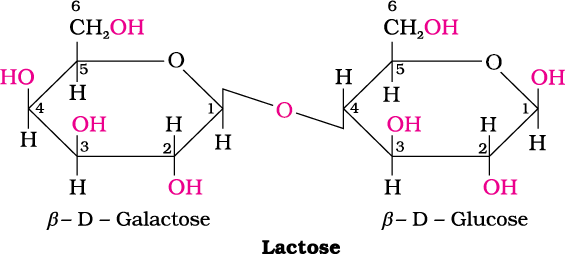
14.1.4 Polysaccharides
Polysaccharides contain a large number of monosaccharide units joined together by glycosidic linkages. These are the most commonly encountered carbohydrates in nature. They mainly act as the food storage or structural materials.
(i) Starch: Starch is the main storage polysaccharide of plants. It is the most important dietary source for human beings. High content of starch is found in cereals, roots, tubers and some vegetables. It is a polymer of α-glucose and consists of two components—Amylose and Amylopectin. Amylose is water soluble component which constitutes about 15-20% of starch. Chemically amylose is a long unbranched chain with 200-1000 α-D-(+)-glucose units held together by C1– C4 glycosidic linkage.
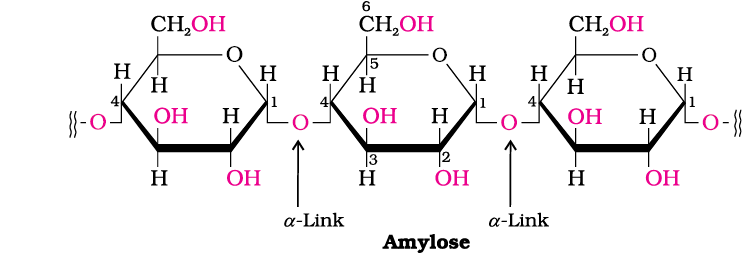
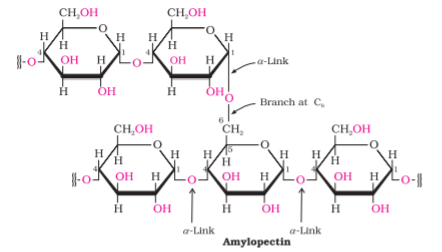
Amylopectin is insoluble in water and constitutes about 80-85% of starch. It is a branched chain polymer of α-D-glucose units in which chain is formed by C1–C4 glycosidic linkage whereas branching occurs by C1–C6 glycosidic linkage.
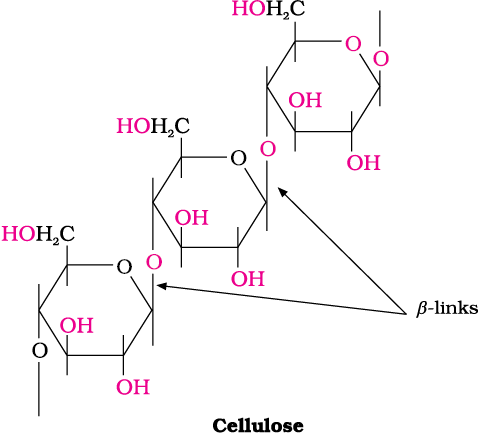
(ii) Cellulose: Cellulose occurs exclusively in plants and it is the most abundant organic substance in plant kingdom. It is a predominant constituent of cell wall of plant cells. Cellulose is a straight chain polysaccharide composed only of β-D-glucose units which are joined by glycosidic linkage between C1 of one glucose unit and C4 of the next glucose unit.
(iii) Glycogen: The carbohydrates are stored in animal body as glycogen. It is also known as animal starch because its structure is similar to amylopectin and is rather more highly branched. It is present in liver, muscles and brain. When the body needs glucose, enzymes break the glycogen down to glucose. Glycogen is also found in yeast and fungi.
14.1.5 Importance of Carbohydrates
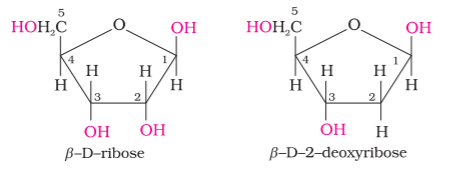
Two aldopentoses viz. D-ribose and 2-deoxy-D-ribose (Section 14.5.1, Class XII) are present in nucleic acids. Carbohydrates are found in biosystem in combination with many proteins and lipids.
Intext Questions
14.1 Glucose or sucrose are soluble in water but cyclohexane or benzene (simple six membered ring compounds) are insoluble in water. Explain.
14.2 What are the expected products of hydrolysis of lactose?
14.3 How do you explain the absence of aldehyde group in the pentaacetate of D-glucose?
14.2 Proteins
Proteins are the most abundant biomolecules of the living system. Chief sources of proteins are milk, cheese, pulses, peanuts, fish, meat, etc. They occur in every part of the body and form the fundamental basis of structure and functions of life. They are also required for growth and maintenance of body. The word protein is derived from Greek word, “proteios” which means primary or of prime importance. All proteins are polymers of α-amino acids.
14.2.1 Amino Acids
Amino acids contain amino (–NH2) and carboxyl (–COOH) functional groups. Depending upon the relative position of amino group with respect to carboxyl group, the amino acids can be classified as α, β, γ, δ and so on. Only α-amino acids are obtained on hydrolysis of proteins. They may contain other functional groups also.
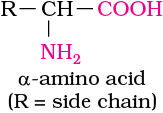
All α-amino acids have trivial names, which usually reflect the property of that compound or its source. Glycine is so named since it has sweet taste (in Greek glykos means sweet) and tyrosine was first obtained from cheese (in Greek, tyros means cheese.) Amino acids are generally represented by a three letter symbol, sometimes one letter symbol is also used. Structures of some commonly occurring amino acids along with their 3-letter and 1-letter symbols are given in Table 14.2.
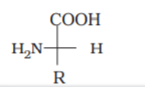
| Name of the amino acids | Characteristic feature of the side chain, R | Three letter symbol | One letter code |
|---|---|---|---|
| 1.Glycine | H | Gly | G |
| 2.Alanine | – CH3 |
Ala | A |
| 3. Valine* | (H3C)2CH- | Val | V |
| 4. Leucine* | (H3C)2CH-CH2- | Leu | L |
| 5. Isoleucine* |  |
Ile |
I |
6. Arginine*
|
 |
Arg
|
R
|
| 7. Lysine* | H2N-(CH2)4- | Lys | K |
| 8. Glutamic acid | HOOC-CH2-CH2- | Glu | E |
| 9. Aspartic acid | HOOC-CH2- | Asp | D |
| 10. Glutamine | 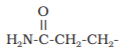 |
Gln | Q |
| 11. Asparagine | 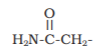 |
Asn | N |
| 12. Threonine* | H3C-CHOH- | Thr | T |
| 13. Serine | HO-CH2- | Ser | S |
| 14. Cysteine | HS-CH2- | Cys | C |
| 15. Methionine* | H3C-S-CH2-CH2- | Met | M |
| 16. Phenylalanine* | C6H5-CH2- | Phe | F |
| 17. Tyrosine | (p)HO-C6H4-CH2- | Tyr | Y |
| 18. Tryptophan* | 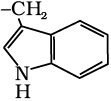 |
Trp | W |
| 19. Histidine* | 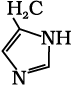 |
His | H |
| 20. Proline | 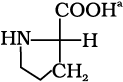 |
Pro | P |
14.2.2 Classification of Amino Acids
Amino acids are classified as acidic, basic or neutral depending upon the relative number of amino and carboxyl groups in their molecule. Equal number of amino and carboxyl groups makes it neutral; more number of amino than carboxyl groups makes it basic and more carboxyl groups as compared to amino groups makes it acidic. The amino acids, which can be synthesised in the body, are known as non-essential amino acids. On the other hand, those which cannot be synthesised in the body and must be obtained through diet, are known as essential amino acids (marked with asterisk in Table 14.2).
Amino acids are usually colourless, crystalline solids. These are water-soluble, high melting solids and behave like salts rather than simple amines or carboxylic acids. This behaviour is due to the presence of both acidic (carboxyl group) and basic (amino group) groups in the same molecule. In aqueous solution, the carboxyl group can lose a proton and amino group can accept a proton, giving rise to a dipolar ion known as zwitter ion. This is neutral but contains both positive and negative charges.
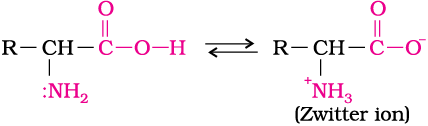
In zwitter ionic form, amino acids show amphoteric behaviour as they react both with acids and bases.
Except glycine, all other naturally occurring α-amino acids are optically active, since the α-carbon atom is asymmetric. These exist both in ‘D’ and ‘L’ forms. Most naturally occurring amino acids have L-configuration. L-Aminoacids are represented by writing the –NH2 group on left hand side.
14.2.3 Structure of Proteins
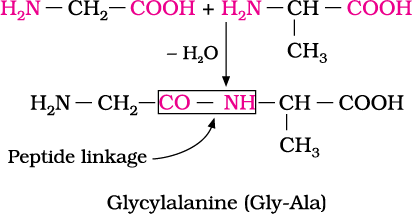
If a third amino acid combines to a dipeptide, the product is called a tripeptide. A tripeptide contains three amino acids linked by two peptide linkages. Similarly when four, five or six amino acids are linked, the respective products are known as tetrapeptide, pentapeptide or hexapeptide, respectively. When the number of such amino acids is more than ten, then the products are called polypeptides. A polypeptide with more than hundred amino acid residues, having molecular mass higher than 10,000u is called a protein. However, the distinction between a polypeptide and a protein is not very sharp. Polypeptides with fewer amino acids are likely to be called proteins if they ordinarily have a well defined conformation of a protein such as insulin which contains 51 amino acids.
Proteins can be classified into two types on the basis of their molecular shape.
(a) Fibrous proteins
When the polypeptide chains run parallel and are held together by hydrogen and disulphide bonds, then fibre– like structure is formed. Such proteins are generally insoluble in water. Some common examples are keratin (present in hair, wool, silk) and myosin (present in muscles), etc.
(b) Globular proteins
This structure results when the chains of polypeptides coil around to give a spherical shape. These are usually soluble in water. Insulin and albumins are the common examples of globular proteins.
Structure and shape of proteins can be studied at four different levels, i.e., primary, secondary, tertiary and quaternary, each level being more complex than the previous one.
 and –NH– groups of the peptide bond.
and –NH– groups of the peptide bond.
In β-pleated sheet structure all peptide chains are stretched out to nearly maximum extension and then laid side by side which are held together by intermolecular hydrogen bonds. The structure resembles the pleated folds of drapery and therefore is known as β-pleated sheet.
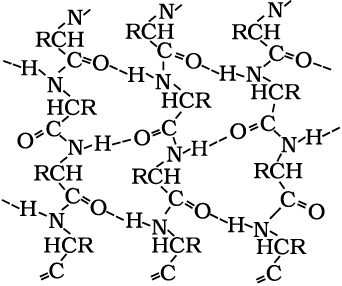
Fig. 14.2: β-Pleated sheet structure of proteins
(iii) Tertiary structure of proteins: The tertiary structure of proteins represents overall folding of the polypeptide chains i.e., further folding of the secondary structure. It gives rise to two major molecular shapes viz. fibrous and globular. The main forces which stabilise the 2° and 3° structures of proteins are hydrogen bonds, disulphide linkages, van der Waals and electrostatic forces of attraction.
(iv) Quaternary structure of proteins: Some of the proteins are composed of two or more polypeptide chains referred to as sub-units. The spatial arrangement of these subunits with respect to each other is known as quaternary structure.
A diagrammatic representation of all these four structures is given in Figure 14.3 where each coloured ball represents an amino acid.

Fig. 14.3: Diagrammatic representation of protein structure (two sub-units of two types in quaternary structure)
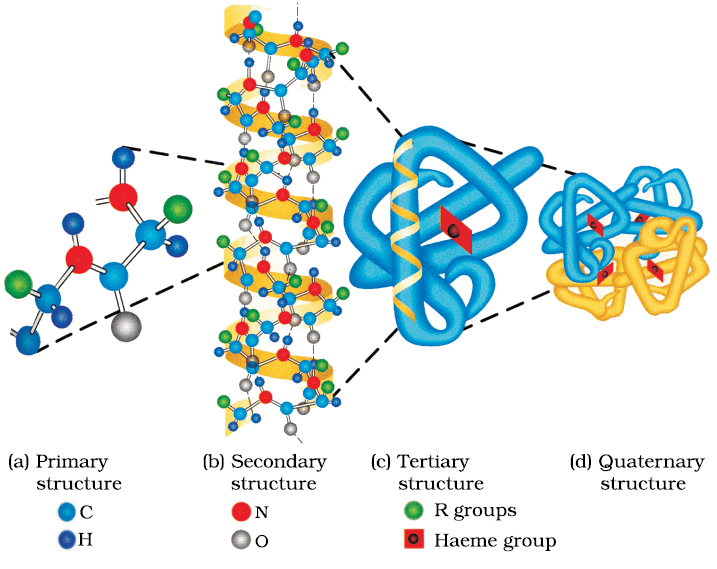
Fig. 14.4: Primary, secondary, tertiary and quaternary structures of haemoglobin
14.2.4 Denaturation of Proteins
Protein found in a biological system with a unique three-dimensional structure and biological activity is called a native protein. When a protein in its native form, is subjected to physical change like change in temperature or chemical change like change in pH, the hydrogen bonds are disturbed. Due to this, globules unfold and helix get uncoiled and protein loses its biological activity. This is called denaturation of protein. During denaturation secondary and tertiary structures are destroyed but primary structure remains intact. The coagulation of egg white on boiling is a common example of denaturation. Another example is curdling of milk which is caused due to the formation of lactic acid by the bacteria present in milk.
Intext Questions
14.4 The melting points and solubility in water of amino acids are generally higher than that of the corresponding halo acids. Explain.
14.5 Where does the water present in the egg go after boiling the egg?
14.3 Enzymes
Life is possible due to the coordination of various chemical reactions in living organisms. An example is the digestion of food, absorption of appropriate molecules and ultimately production of energy. This process involves a sequence of reactions and all these reactions occur in the body under very mild conditions. This occurs with the help of certain biocatalysts called enzymes. Almost all the enzymes are globular proteins. Enzymes are very specific for a particular reaction and for a particular substrate. They are generally named after the compound or class of compounds upon which they work. For example, the enzyme that catalyses hydrolysis of maltose into glucose is named as maltase.

Sometimes enzymes are also named after the reaction, where they are used. For example, the enzymes which catalyse the oxidation of one substrate with simultaneous reduction of another substrate are named as oxidoreductase enzymes. The ending of the name of an enzyme is -ase.
14.3.1 Mechanism of Enzyme Action
Enzymes are needed only in small quantities for the progress of a reaction. Similar to the action of chemical catalysts, enzymes are said to reduce the magnitude of activation energy. For example, activation energy for acid hydrolysis of sucrose is 6.22 kJ mol–1, while the activation energy is only 2.15 kJ mol–1 when hydrolysed by the enzyme, sucrase. Mechanism for the enzyme action has been discussed in Unit 5.
14.4 Vitamins
It has been observed that certain organic compounds are required in small amounts in our diet but their deficiency causes specific diseases. These compounds are called vitamins. Most of the vitamins cannot be synthesised in our body but plants can synthesise almost all of them, so they are considered as essential food factors. However, the bacteria of the gut can produce some of the vitamins required by us. All the vitamins are generally available in our diet. Different vitamins belong to various chemical classes and it is difficult to define them on the basis of structure. They are generally regarded as organic compounds required in the diet in small amounts to perform specific biological functions for normal maintenance of optimum growth and health of the organism. Vitamins are designated by alphabets A, B, C, D, etc. Some of them are further named as sub-groups e.g. B1, B2, B6, B12, etc. Excess of vitamins is also harmful and vitamin pills should not be taken without the advice of doctor.
The term “Vitamine” was coined from the word vital + amine since the earlier identified compounds had amino groups. Later work showed that most of them did not contain amino groups, so the letter ‘e’ was dropped and the term vitamin is used these days.
14.4.1 Classification of Vitamins
Vitamins are classified into two groups depending upon their solubility in water or fat.
(i) Fat soluble vitamins: Vitamins which are soluble in fat and oils but insoluble in water are kept in this group. These are vitamins A, D, E and K. They are stored in liver and adipose (fat storing) tissues.
(ii) Water soluble vitamins: B group vitamins and vitamin C are soluble in water so they are grouped together. Water soluble vitamins must be supplied regularly in diet because they are readily excreted in urine and cannot be stored (except vitamin B12) in our body.
Some important vitamins, their sources and diseases caused by their deficiency are listed in Table 14.3.
Table 14.3: Some important Vitamins, their Sources and their Deficiency Diseases
14.5 Nucleic Acids
Every generation of each and every species resembles its ancestors in many ways. How are these characteristics transmitted from one generation to the next? It has been observed that nucleus of a living cell is responsible for this transmission of inherent characters, also called heredity. The particles in nucleus of the cell, responsible for heredity, are called chromosomes which are made up of proteins and another type of biomolecules called nucleic acids. These are mainly of two types, the deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). Since nucleic acids are long chain polymers of nucleotides, so they are also called polynucleotides.
James Dewey Watson
 Born in Chicago, Illinois, in 1928, Dr Watson received his Ph.D. (1950) from Indiana University in Zoology. He is best known for his discovery of the structure of DNA for which he shared with Francis Crick and Maurice Wilkins the 1962 Nobel prize in Physiology and Medicine. They proposed that DNA molecule takes the shape of a double helix, an elegantly simple structure that resembles a gently twisted ladder. The rails of the ladder are made of alternating units of phosphate and the sugar deoxyribose; the rungs are each composed of a pair of purine/ pyrimidine bases. This research laid the foundation for the emerging field of molecular biology. The complementary pairing of nucleotide bases explains how identical copies of parental DNA pass on to two daughter cells. This research launched a revolution in biology that led to modern recombinant DNA techniques.
Born in Chicago, Illinois, in 1928, Dr Watson received his Ph.D. (1950) from Indiana University in Zoology. He is best known for his discovery of the structure of DNA for which he shared with Francis Crick and Maurice Wilkins the 1962 Nobel prize in Physiology and Medicine. They proposed that DNA molecule takes the shape of a double helix, an elegantly simple structure that resembles a gently twisted ladder. The rails of the ladder are made of alternating units of phosphate and the sugar deoxyribose; the rungs are each composed of a pair of purine/ pyrimidine bases. This research laid the foundation for the emerging field of molecular biology. The complementary pairing of nucleotide bases explains how identical copies of parental DNA pass on to two daughter cells. This research launched a revolution in biology that led to modern recombinant DNA techniques.
14.5.1 Chemical Composition of Nucleic Acids
Complete hydrolysis of DNA (or RNA) yields a pentose sugar, phosphoric acid and nitrogen containing heterocyclic compounds (called bases). In DNA molecules, the sugar moiety is β-D-2-deoxyribose whereas in RNA molecule, it is β-D-ribose.
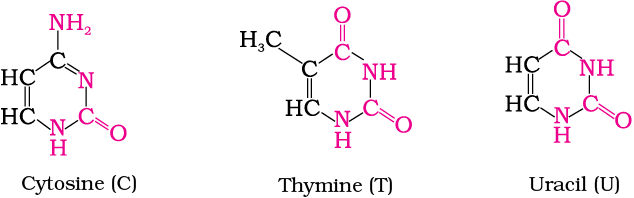
DNA contains four bases viz. adenine (A), guanine (G), cytosine (C) and thymine (T). RNA also contains four bases, the first three bases are same as in DNA but the fourth one is uracil (U).

14.5.2 Structure of Nucleic Acids
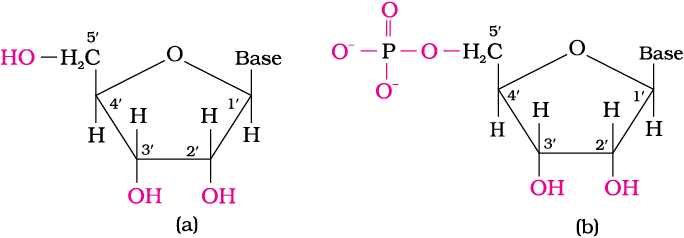
Fig. 14.5: Structure of (a) a nucleoside and (b) a nucleotide
Nucleotides are joined together by phosphodiester linkage between 5′ and 3′ carbon atoms of the pentose sugar. The formation of a typical dinucleotide is shown in Fig. 14.6.
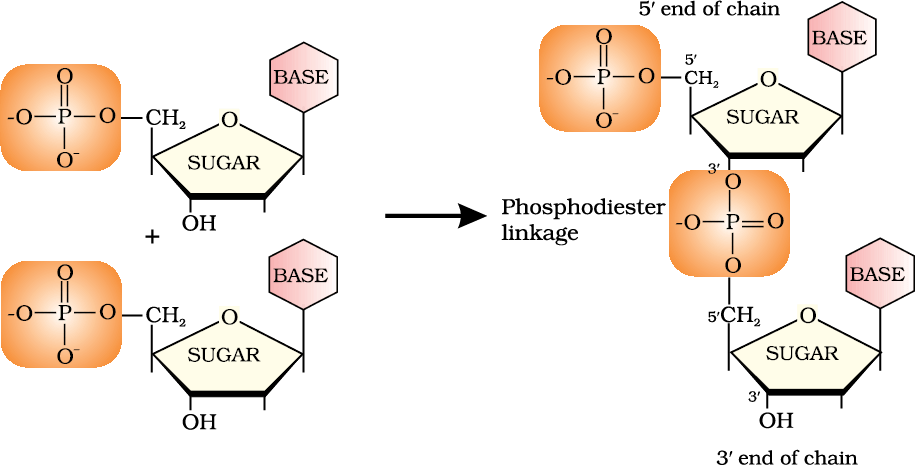
Fig. 14.6: Formation of a dinucleotide
A simplified version of nucleic acid chain is as shown below.
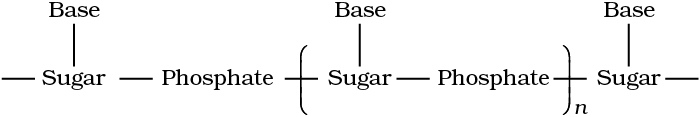

Fig. 14.7: Double strand helix structure for DNA
In secondary structure of RNA single stranded helics is present which sometimes foldsback on itself. RNA molecules are of three types and they perform different functions. They are named as messenger RNA (m-RNA), ribosomal RNA (r-RNA) and transfer RNA (t-RNA).

Har Gobind Khorana
Har Gobind Khorana, was born in 1922. He obtained his M.Sc. degree from Punjab University in Lahore. He worked with Professor Vladimir Prelog, who moulded Khorana’s thought and philosophy towards science, work and effort. After a brief stay in India in 1949, Khorana went back to England and worked with Professor G.W. Kenner and Professor A.R.Todd. It was at Cambridge, U.K. that he got interested in both proteins and nucleic acids. Dr Khorana shared the Nobel Prize for Medicine and Physiology in 1968 with Marshall Nirenberg and Robert Holley for cracking the genetic code.
DNA Fingerprinting
It is known that every individual has unique fingerprints. These occur at the tips of the fingers and have been used for identification for a long time but these can be altered by surgery. A sequence of bases on DNA is also unique for a person and information regarding this is called DNA fingerprinting. It is same for every cell and cannot be altered by any known treatment. DNA fingerprinting is now used
(i) in forensic laboratories for identification of criminals.
(ii) to determine paternity of an individual.
(iii) to identify the dead bodies in any accident by comparing the DNA’s of parents or children.
(iv) to identify racial groups to rewrite biological evolution.
14.5.3 Biological Functions of Nucleic Acids
DNA is the chemical basis of heredity and may be regarded as the reserve of genetic information. DNA is exclusively responsible for maintaining the identity of different species of organisms over millions of years. A DNA molecule is capable of self duplication during cell division and identical DNA strands are transferred to daughter cells. Another important function of nucleic acids is the protein synthesis in the cell. Actually, the proteins are synthesised by various RNA molecules in the cell but the message for the synthesis of a particular protein is present in DNA.
14.6 Hormones
Hormones are molecules that act as intercellular messengers. These are produced by endocrine glands in the body and are poured directly in the blood stream which transports them to the site of action.
In terms of chemical nature, some of these are steroids, e.g., estrogens and androgens; some are poly peptides for example insulin and endorphins and some others are amino acid derivatives such as epinephrine and norepinephrine.
Hormones have several functions in the body. They help to maintain the balance of biological activities in the body. The role of insulin in keeping the blood glucose level within the narrow limit is an example of this function. Insulin is released in response to the rapid rise in blood glucose level. On the other hand hormone glucagon tends to increase the glucose level in the blood. The two hormones together regulate the glucose level in the blood. Epinephrine and norepinephrine mediate responses to external stimuli. Growth hormones and sex hormones play role in growth and development. Thyroxine produced in the thyroid gland is an iodinated derivative of amino acid tyrosine. Abnormally low level of thyroxine leads to hypothyroidism which is characterised by lethargyness and obesity. Increased level of thyroxine causes hyperthyroidism. Low level of iodine in the diet may lead to hypothyroidism and enlargement of the thyroid gland. This condition is largely being controlled by adding sodium iodide to commercial table salt (“Iodised” salt).
Steroid hormones are produced by adrenal cortex and gonads (testes in males and ovaries in females). Hormones released by the adrenal cortex play very important role in the functions of the body. For example, glucocorticoids control the carbohydrate metabolism, modulate inflammatory reactions, and are involved in reactions to stress. The mineralocorticoids control the level of excretion of water and salt by the kidney. If adrenal cortex does not function properly then one of the results may be Addison’s disease characterised by hypoglycemia, weakness and increased susceptibility to stress. The disease is fatal unless it is treated by glucocorticoids and mineralocorticoids. Hormones released by gonads are responsible for development of secondary sex characters. Testosterone is the major sex hormone produced in males. It is responsible for development of secondary male characteristics (deep voice, facial hair, general physical constitution) and estradiol is the main female sex hormone. It is responsible for development of secondary female characteristics and participates in the control of menstrual cycle. Progesterone is responsible for preparing the uterus for implantation of fertilised egg.
14.6 Why cannot vitamin C be stored in our body?
14.7 What products would be formed when a nucleotide from DNA containing thymine is hydrolysed?
14.8 When RNA is hydrolysed, there is no relationship among the quantities of different bases obtained. What does this fact suggest about the structure of RNA?
Summary
Carbohydrates are optically active polyhydroxy aldehydes or ketones or molecules which provide such units on hydrolysis. They are broadly classified into three groups — monosaccharides, disaccharides and polysaccharides. Glucose, the most important source of energy for mammals, is obtained by the digestion of starch. Monosaccharides are held together by glycosidic linkages to form disaccharides or polysaccharides.
Proteins are the polymers of about twenty different α-amino acids which are linked by peptide bonds. Ten amino acids are called essential amino acids because they cannot be synthesised by our body, hence must be provided through diet. Proteins perform various structural and dynamic functions in the organisms. Proteins which contain only α-amino acids are called simple proteins. The secondary or tertiary structure of proteins get disturbed on change of pH or temperature and they are not able to perform their functions. This is called denaturation of proteins. Enzymes are biocatalysts which speed up the reactions in biosystems. They are very specific and selective in their action and chemically all enzymes are proteins.
Vitamins are accessory food factors required in the diet. They are classified as fat soluble (A, D, E and K) and water soluble (Β group and C). Deficiency of vitamins leads to many diseases.
Nucleic acids are the polymers of nucleotides which in turn consist of a base, a pentose sugar and phosphate moiety. Nucleic acids are responsible for the transfer of characters from parents to offsprings. There are two types of nucleic acids — DNA and RNA. DNA contains a five carbon sugar molecule called 2-deoxyribose whereas RNA contains ribose. Both DNA and RNA contain adenine, guanine and cytosine. The fourth base is thymine in DNA and uracil in RNA. The structure of DNA is a double strand whereas RNA is a single strand molecule. DNA is the chemical basis of heredity and have the coded message for proteins to be synthesised in the cell. There are three types of RNA — mRNA, rRNA and tRNA which actually carry out the protein synthesis in the cell.
Exercises
14.1 What are monosaccharides?
14.2 What are reducing sugars?
14.3 Write two main functions of carbohydrates in plants.
14.4 Classify the following into monosaccharides and disaccharides.
Ribose, 2-deoxyribose, maltose, galactose, fructose and lactose.
14.5 What do you understand by the term glycosidic linkage?
14.6 What is glycogen? How is it different from starch?
14.7 What are the hydrolysis products of
(i) sucrose and (ii) lactose?
14.8 What is the basic structural difference between starch and cellulose?
14.9 What happens when D-glucose is treated with the following reagents?
(i) HI (ii) Bromine water (iii) HNO3
14.10 Enumerate the reactions of D-glucose which cannot be explained by its open chain structure.
14.11 What are essential and non-essential amino acids? Give two examples of each type.
14.12 Define the following as related to proteins
(i) Peptide linkage (ii) Primary structure (iii) Denaturation.
14.13 What are the common types of secondary structure of proteins?
14.14 What type of bonding helps in stabilising the α-helix structure of proteins?
14.15 Differentiate between globular and fibrous proteins.
14.16 How do you explain the amphoteric behaviour of amino acids?
14.17 What are enzymes?
14.18 What is the effect of denaturation on the structure of proteins?
14.19 How are vitamins classified? Name the vitamin responsible for the coagulation of blood.
14.20 Why are vitamin A and vitamin C essential to us? Give their important sources.
14.21 What are nucleic acids? Mention their two important functions.
14.22 What is the difference between a nucleoside and a nucleotide?
14.23 The two strands in DNA are not identical but are complementary. Explain.
14.24 Write the important structural and functional differences between DNA and RNA.
14.25 What are the different types of RNA found in the cell?